Here’s a link to the problem.
With problems like these, it’s often useful to consider extreme tree configurations, such as:
1. Long Chain
This case is easily solved via binary search.
2. Star Graph
Without the condition that the mole moves upward when our query misses, star graphs (i.e. trees of depth 1) would be impossible to solve in faster than queries. Luckily, the fact that the mole moves up means that we can actually solve any star graph in at most 2 queries!
So, it looks like if we want to figure out a worst-case scenario, we’ll need to balance out depth (long chains) and breadth (star graphs). One way we can achieve this is to construct a tree with chains of nodes connected to the root, like so:
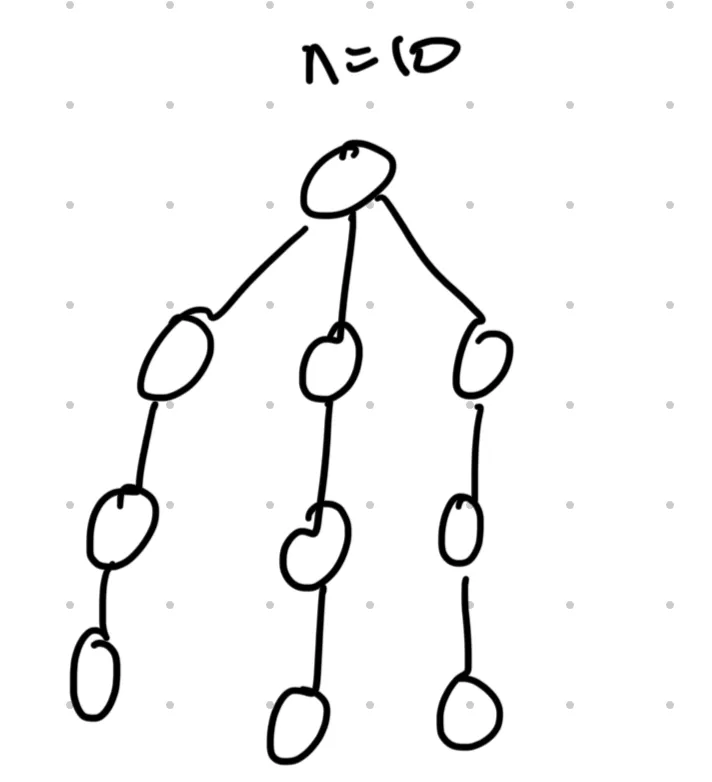 Such a tree requires us to make queries in the worst case since we have to check all the branches, and in that time the mole may not reach the root.
Such a tree requires us to make queries in the worst case since we have to check all the branches, and in that time the mole may not reach the root.
So now the question becomes: can we always achieve this lower bound of queries?
As it turns out, yes! And an even more beautiful fact is that if, at every time-step, we simply make the query that eliminates as many nodes as possible, we can achieve this bound.
However, I’d first like to offer my slightly less elegant approach:
Let denote the set of leaves of the subgraph where the mole could currently be located---that is, the mole could be in any of these nodes, or their ancestors. The key idea is that we can always query a node such that we either
- Reduce our search space to a single chain, to which we can apply a simple binary search.
- Remove a single leaf from , then replace all elements of with their parents.
To select , we simply choose a leaf in , then set to be the highest ancestor of that contains only one leaf in .
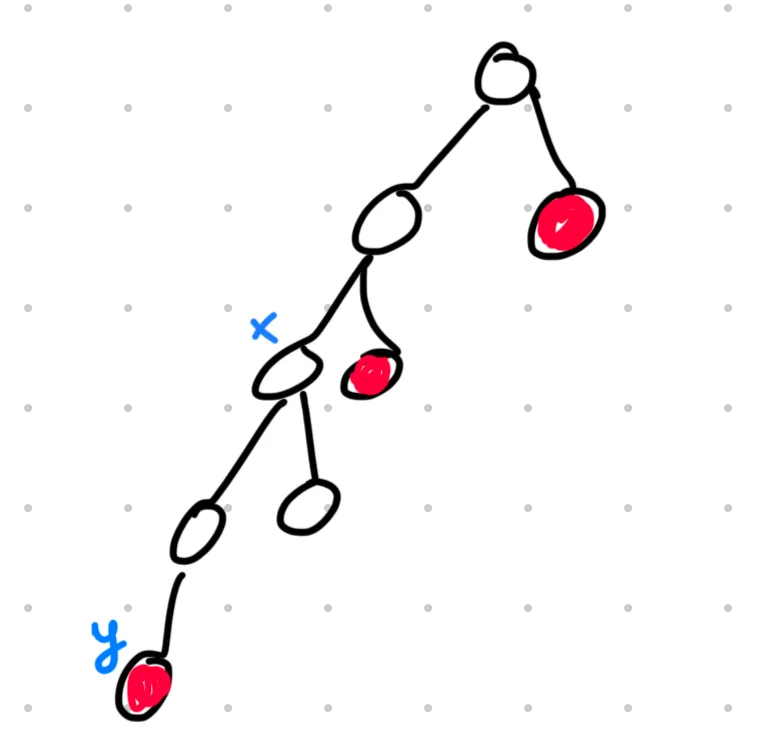 The red nodes denote the elements of . One possible choice of and is shown.
The red nodes denote the elements of . One possible choice of and is shown.
If we query and get response 1, we know the mole must be somewhere along the chain between and .
Otherwise, we eliminate from , and since the mole must move up, all elements of are replaced with their parents.
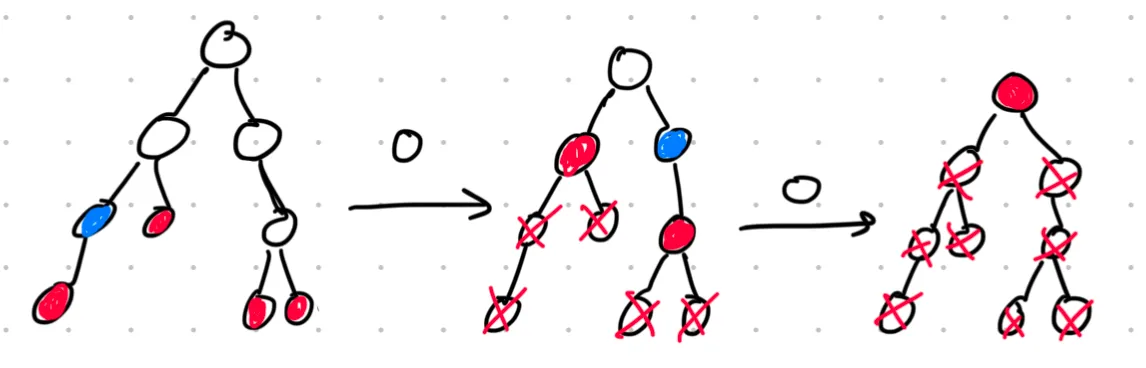 An illustration of the process described above. Red nodes denote elements of , and the blue node denotes , the node we query in each step.
An illustration of the process described above. Red nodes denote elements of , and the blue node denotes , the node we query in each step.
Let denote after the th query. Assume all queries have returned 0, since as soon as a query returns 1, we can find the mole in queries. Then, we have that
- All are disjoint, and thus
Combining these two facts, we can show that using our strategy, no more than queries can return 0. Thus, our total runtime is .
The one thing I dislike about this approach is that a separate strategy (binary search) is needed to handle the chain case. However, this is not an issue for the strategy I mentioned above, where we always greedily eliminate as many nodes as possible. Here’s a nice proof for why this works, which I got from here:
Let’s consider a slight rephrasing of the problem. In each step, we can either 1) query a subtree and know whether it contains the mole or not, or 2) delete all leaves from the tree.
If we do operation 1 on a subtree of size , we will eliminate, in the worst case, nodes. This means that, as long as there exists some subtree that is not “too small” nor “too large”, we can always eliminate a decent amount of nodes. However, let’s say this is not the case, and all subtrees are either too large or too small (for instance, a star graph). Then, there must exist a large subtree whose children are all small, and the root of this subtree must then have significant degree. This means the tree must have a significant number of leaves, which we can then eliminate via operation 2!
Let’s formalize this, and define a “small” subtree as one with size , and a “large” subtree as one with size . Then, if a large subtree has only small subtrees as children, its root must have a degree of at least , which means there must be at least leaves! Therefore, we can always remove at least nodes in each step, and so greedily maximizing the number of nodes deleted in each round suffices.
To summarize concisely why this approach works: unless some node has very high degree, a tree’s subtree sizes will be relatively continuous. IMO, a pretty elegant fact!